



Whether you're launching a new blog, optimizing product pages, or developing a data-driven SEO strategy, keyword research is a critical step. But gath
Whether you’re launching a new blog, optimizing product pages, or developing a data-driven SEO strategy, keyword research is a critical step. But gathering keyword ideas manually from multiple sources is inefficient and often incomplete. This is where a keyword lists crawler becomes a valuable asset—automating the collection and organization of keyword data across web sources.
In this article, we’ll explain what keyword list crawlers are, how they function, their benefits, and how to use them effectively across various digital marketing and SEO projects.
Must visitt: trustedhealthcare
What Is a Keyword Lists Crawler?
A keyword lists crawler is a tool (or script) designed to scan and extract keywords from specified web pages or online sources. Unlike traditional SEO tools that provide keyword suggestions from internal databases, crawlers collect live keyword data directly from websites, including competitor content, metadata, headings, and other relevant page elements.
In short, it’s a web crawling tool with a specific focus: to mine useful keywords from the internet, organize them, and deliver actionable insights for SEO, content development, or PPC advertising.
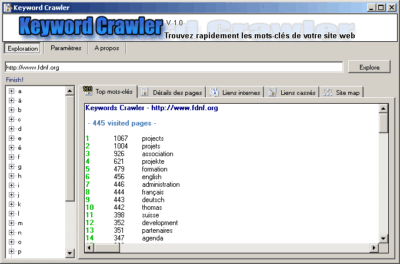
lists crawler
How a Keyword Lists Crawler Works
While implementations can vary, most keyword crawlers follow a standard process:
1. Input URLs or Seed Keywords
You start by feeding the crawler with:
- A list of URLs to crawl
- A keyword or phrase to use as a search seed
- A website domain to crawl site-wide
2. Crawling the Content
The crawler sends HTTP requests to fetch the HTML of each page. It reads through structured elements like:
- <title>
- <meta description>
- <h1>, <h2>, and other heading tags
- Paragraph text
- Anchor text
- Alt tags (for images)
3. Text Parsing and Tokenization
Text content is processed by breaking it into individual words or phrases (called tokens). Common stopwords (like “and”, “the”, “it”) are removed, and the remaining keywords are analyzed.
4. Keyword Grouping
Words are grouped based on frequency, similarity, or placement. Some advanced crawlers cluster keywords by topic or intent (informational, navigational, or transactional).
5. Output
The final result is a structured keyword list you can export in formats like CSV, Excel, or JSON for further analysis.
Why Use a Keyword Lists Crawler?
Keyword crawlers aren’t just for technical SEOs—they benefit marketers, bloggers, ad strategists, and business owners. Here are the key advantages:
✅ Uncover Real-World Language
Instead of relying solely on database tools, crawlers collect words and phrases actually used by users and businesses in real content.
✅ Monitor Competitor Strategy
Extract keywords from top-performing competitors’ websites to identify what’s driving their visibility and how you can compete.
✅ Find Long-Tail and Semantic Keywords
Keyword crawlers can uncover low-competition, long-tail phrases that keyword suggestion tools might miss.
✅ Support Topic Clustering
By analyzing headings, subheadings, and on-page text, crawlers help you build topical authority by grouping related terms.
✅ Scale Research Efforts
Crawl hundreds of pages in less time than it takes to manually review a handful of them.
Popular Use Cases
Here are practical ways marketers and content creators use keyword crawlers:
🔹 Blog Planning
Use crawlers to mine keywords from forums, Q&A sites, or blogs for content ideas that align with what people are asking.
🔹 E-commerce SEO
Crawl product descriptions and reviews from marketplaces to find descriptive, high-intent keywords for product pages.
🔹 SERP Analysis
Extract keywords from search engine result pages to discover what kind of content ranks for a specific term.
🔹 Landing Page Optimization
Analyze competitor landing pages to understand the keyword choices driving conversions.
🔹 Local SEO
Scan local business directories or service provider sites to identify location-specific keywords.
Keyword Crawler Features to Look For
If you’re choosing a keyword list crawler—either a tool or one to build—these features are essential:
- Custom crawl depth
Limit how far a crawler navigates through internal links. - Stopword and duplicate filters
Clean your keyword data by eliminating low-value words. - Tag-specific scraping
Extract only from specific HTML tags for better relevance. - Multi-language support
Useful for international SEO and multilingual sites. - Export options
Look for flexible outputs (CSV, JSON, Google Sheets) for easy integration with your workflow. - Frequency analysis
Group keywords by how often they appear and where (title vs body).
Challenges and Ethical Considerations
Keyword crawling offers tremendous value, but it comes with responsibilities and technical challenges:
⚠️ Legal Restrictions
Always check and respect a website’s robots.txt file. Scraping data from restricted sites without permission could violate terms of service or local laws.
⚠️ Bot Detection
Many websites use tools to block automated crawlers. You may need to use rotating proxies, headers, or browser automation tools to avoid detection (especially for large-scale crawls).
⚠️ Data Overload
Without clear filters or scope, crawlers can return massive keyword lists—many of which may be redundant or irrelevant. Use filters and focus to keep data manageable.
Keyword Crawlers vs Traditional SEO Tools
| Feature | Keyword Crawler | Traditional Keyword Tool |
| Data Source | Live web content | Internal database/API |
| Customization | Highly customizable | Pre-defined functions |
| Long-tail Discovery | Strong | Moderate |
| Competitor Keyword Mining | Yes | Limited |
| Data Accuracy | Varies by source | Usually high (via search engines) |
| SERP Integration | Requires scraping/API | Often built-in |
Conclusion: Keyword crawlers and SEO tools are best used together. Crawlers find unique keywords in real-world use, while SEO tools help assess keyword volume and competitiveness.
FAQs: Keyword Lists Crawler
1. Do I need coding skills to use a keyword crawler?
Not necessarily. Many keyword crawlers are available as user-friendly tools. However, if you’re building one from scratch, some knowledge of programming (e.g., Python, JavaScript) is helpful.
2. What is the difference between a web crawler and a keyword crawler?
A web crawler is a general tool that scans websites to collect data like links, images, or content. A keyword crawler focuses specifically on extracting keywords and textual information for SEO or marketing purposes.
3. How many pages can I crawl at once?
This depends on the tool and the server you’re accessing. Large-scale crawls may require proxies or delays to avoid getting blocked. A typical safe range is 100–1,000 pages per session, unless otherwise allowed.
4. Can a keyword crawler analyze YouTube or social media content?
Not directly. These platforms use dynamic loading and APIs. However, some tools can extract data using APIs or browser automation to simulate user behavior and capture content for keyword analysis.
5. How do I choose which pages to crawl?
Start with:
- High-ranking pages for a target keyword
- Competitor product or service pages
- Niche blogs or industry sites
- Forum threads or community discussions
Define a clear goal before crawling to stay focused.
Final Thoughts
In a digital world where information is everywhere and user behavior evolves rapidly, staying ahead with the right keywords is essential. A keyword lists crawler gives you the power to gather real-time, relevant data from the web and turn it into meaningful strategy.
Used correctly, it can transform how you conduct research—giving you a scalable, automated way to discover hidden keyword opportunities that your competitors might miss. Whether you’re optimizing a few landing pages or running a multi-channel SEO campaign, keyword crawlers help ensure your content is aligned with what your audience is actually searching for.
COMMENTS